第1周-编译原理-3月6日
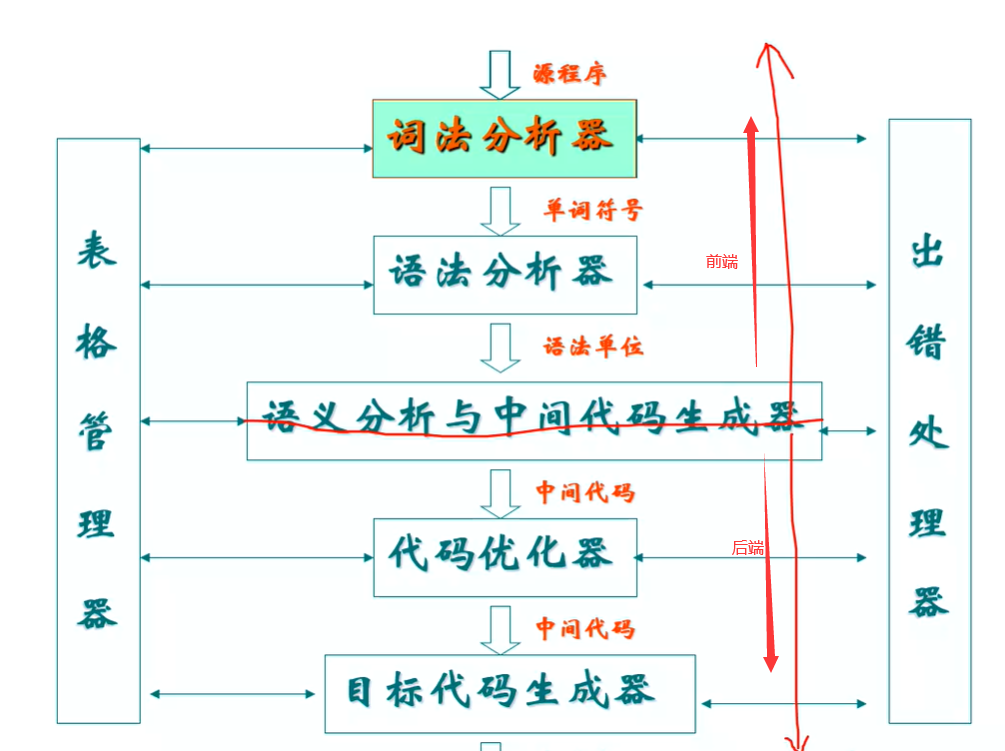
编译程序
一言以蔽之,源代码进,目标代码出。
- 前端:第一阶段源代码进,语法树出(分析源代码的语法结构,并且用一棵语法树表达出来)
- 后端:第二阶段为综合,包括中间代码生成和目标代码生成(语法树进,目标代码出;根据这棵语法树,产生目标代码)
- 前端
- 词法分析(识别出源代码中的一个一个的 token)
词法分析的工具是正则表达式和有限状态自动机。利用它们
来匹配源代码串中的每个部分,把源代码串切成一小段一小
段,每小段视作一个独立意义的词法单元,称为一个token.
每个token是个二元组,由单词和语义值二部分组成。
(把源代码想成一句英语句子,识别出一个句子中每一个英文字母,组成英文单词[token] 并弄清楚每个英文单词的意思)

Ps:词法分析是从左到右吗?是的。 - 语法分析
语法分析的工具是上下文无关文法。利用上下文无关文法把
从词法分析得到的一个个token做成语法树。具体的产生语法
树的方法有多种,但是大体上分为两类:自顶向下和自底向
上产生语法树。大多数方法产生的语法解析树中有多余的信
息,需要进一步做成抽象语法树(Abstract Syntax Tree,简称
为AST),以方便后续动作。
(把一串 token 的语法结构理清楚,然后把理清楚的语法结构用一颗语法树表达出来)
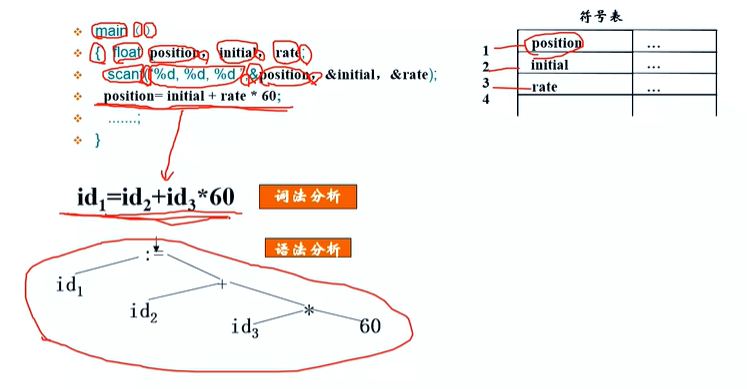
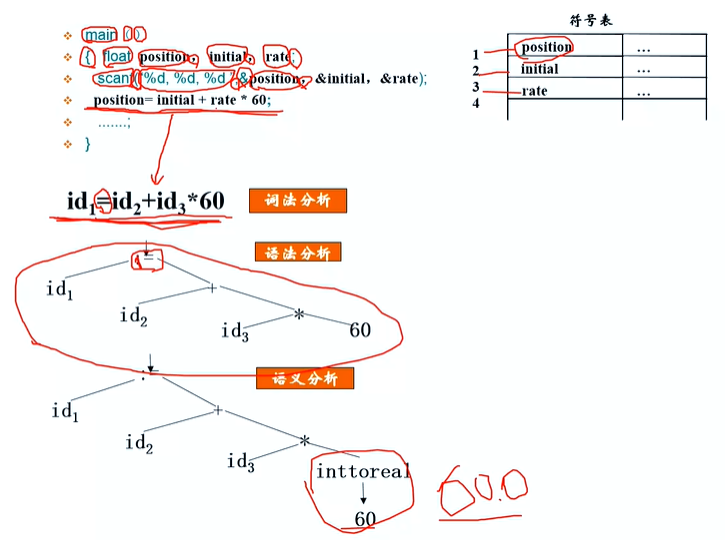
Ps:优先级如何计算:按照加减乘除的优先级运算 - 语义分析(遍历这棵语法树,借助我们保存源代码符号表,检查这棵语法树,是否有语义)
语法树有了,但还不知道它是否合语义,就把它交给语义分
析。进行例如类型检查、变量声明检查等。检查方法是借助
符号表来遍历该语法树,如果发现了错误,准确详细地报告
错误信息,以帮助程序员改正。
(板凳爬上墙-很明显无语意;壁虎爬上墙-有语意)
- 后端
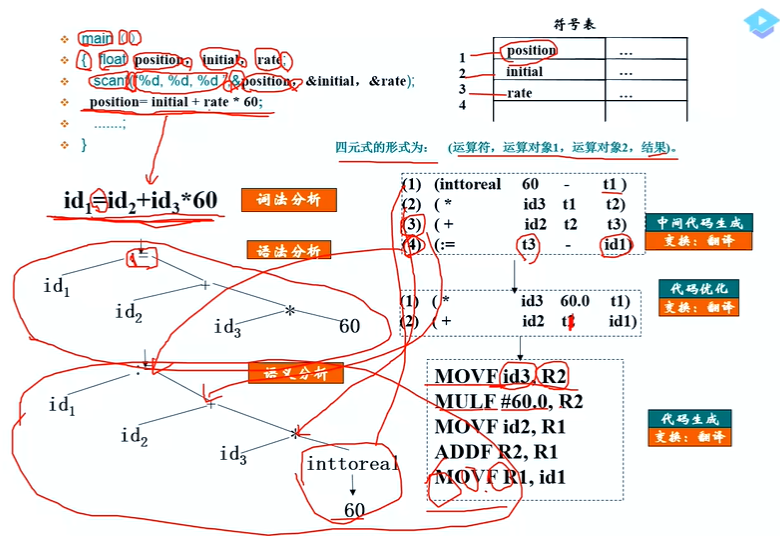
- 中间代码生成(把任何语言翻译成中间代码,根据目标CPU的不同,再把中间代码翻译成目标语言[可以交叉编译])
通过了语义分析,程序在形式,上是确保没错了,那就进行中
间代码生成,以便下一-步方便地生成目标代码。之所以要做
这一步,是为了减少翻译的工作量。假设源代码语言有x种,
目标代码语言有y种,如果直接从源代码生成目标代码,就需
要编写x*y种算法来完成这个直接的翻译工作;而先转为统一
的中间代码后,需要编写的算法数量为x+y种。生成中间代码
的方法还是遍历语法树,为语法树的各个节点指定产生规则
以使在遍历到各个节点时根据指定的产生规则生成正确的
代码。

- 目标代码生成器
版权声明:
作者:三炮不吃鱼
链接:https://www.keke.moe/archives/1241.html
文章版权归作者所有,未经允许请勿转载。
THE END